Under the Hood of Text Analyzer


The Text Analyzer (https://www.jstor.org/analyze) is a new way to search JSTOR: upload your own text or document, Text Analyzer processes the text to find the most significant topics and named entities (persons, locations, organizations) in the text and the recommends similar or related content from JSTOR.
In this post I'll provide a peek under the hood of the analyzer, describing the analysis processes and tools/technologies used. I'll also describe some features that have been incorported into the processing and interface intended to remove much of that black-box feel that often accompany a tool such as this.
How it does what it does
The Text Analyzer performs its processing in 3 main steps.
- The first step involves the extraction of text from a submitted document, unless raw text is provided via direct entry or copy/paste, in which case it is simply passed to step 2.
- Text is extracted from documents using server-side processing. (Note that a submitted document is only retained on our servers long enough for the text to be extracted, and when completed the document is removed from our system.) Text can be extracted from most any document type including PDFs and MS Word documents.
- Text can also be extracted from images using a OCR, which is especially useful when using the Text Analyzer on a mobile phone with a built-in camera.
2. After raw text has been obtained up to 3 separate text analyses are performed in parallel.
- Topics explicitly mentioned in the text are identified using a the JSTOR thesaurus (a controlled vocabulary containing more than 40,000 concepts) and a human-curated set of rules in the MAIstro product from Access Innovations. Using MAIstro, concepts/terms from the JSTOR thesaurus are identified in unstructured text.
- Latent topics are inferred using an LDA (Latent Dirichlet allocation) topic model trained with JSTOR content associated with the terms in our controlled vocabulary. Our application of LDA topic modeling takes advantage of the controlled vocabulary and rules-based document tagging described above. With these tagged documents we are able to use the Labeled LDA (as described here) variant of LDA to train a model using our thesaurus as a predefined set of labels for the model topics.
- Named entities (persons, locations, organizations) are identified using multiple entity recognition services and tools. This includes Alchemy (part of IBMs Watson services), OpenCalais (from Thompson Reuters), the Stanford Named Entity Recognizer, and Apache OpenNLP. Entities recognized by the individual tools/services are aggregated and ranked using a voting scheme and a basic TF-IDF calculation to estimate the relative importance of the entity to the source document.
3. The 5 most significant topics (both those explicitly mentioned in the text and those inferred) and recognized named entities are used in a query to identify similar content from the JSTOR archive.
- A document is selected if at least one of the terms (topics or entities) in the query are found in a document. Using this 'OR'ing approach adding more terms increases the number of documents selected.
- Selected documents are ranked using a scoring calculation that considers both the weight of the term from the input text and the importance of the term in the selected document.
- The weight of the query terms used (from the PRIORITIZED TERMS section of the UI) can be adjusted using the slider widgets. The preselected terms can be also removed and new terms can be added as needed.
- The Text Analyzer uses the top 5 terms identified in the source document based on weights calculated in the 3 analyses described above. These should be viewed as a starting point and adjusted as needed to match a specific area of interest. The Text Analyzer is designed to be used in an iterative process wherein the initial seed terms are augmented, removed or have their weights adjusted.
- A new query is automatically performed after any change in the query terms. After each new query the IDENTIFIED TERMS are updated to include related (co-occurring) topics found in the top results. In that way, the palette of terms available for use in a query are continually updated to reflect current user preferences. A user is also able to enter ad-hoc terms directly using the provided input box.
How it shows its work
- First, the most significant topics and entities found during the text analysis phase are displayed in the IDENTIFIED TERMS section of the UI. The weight and origin of each term can be seen by hovering your cursor over the term. The tooltip shown will identify whether the term was obtained from the source text or whether it was derived from co-occurring topics found in similar documents. If the term was from the source document the tooltip will also identify whether it was a topic explicitly found in the document or was a latent topic inferred using the topic model. In all cases the value of the calculated weight is provided.
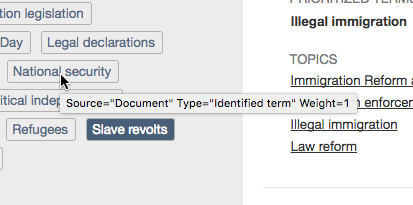
- Here's an example of a tooltip for a term that was identified in the text of the source document. In this example, the term "National security" was found in the source document.
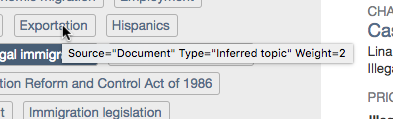
- This is an example of a tooltip for a latent topic that was inferred from the source text using an LDA topic model. In this example, the text "Exportation" was not found in the source document but this topic was inferred from other frequency of words/phrases that are commonly associated with the topic Exportation based on the LDA model.
- And, here's an example of a term ("Immigration legislation") that was neither found in nor inferred from the source document but may be related in some way based on the frequency of co-occurrence of the term in similar documents.

2. In the search to identify similar documents the analyzer uses the terms displayed in the PRIORITIZED TERMS section of the UI. The seed terms that were automatically selected from the IDENTIFIED TERMS can be easily customized (removed, added, weight changed) in the interface to match a users preference. The analyzer attempts to pick the most significant terms but with a vocabulary of more than 40,000 possibilities and the difficulties inherent in natural language processing it will invariably have some misses and/or questionable selections.
The best recommendations are obtained when the terms are tweaked to better align with the content desired. This is done with the controls in the PRIORITIZED TERMS section of the UI. Clicking the 'X' icon next to the term will remove it. Clicking on a term from the IDENTIFIED TERMS section will add it to the list. Ad-hoc terms may also be entered using the "Add your own term" input box. The weight for any term in the list can be adjust using the slider widget.

3. The results returned by the search include detailed information enabling a user to see why each document was selected and how its relevancy score was calculated resulting in its relative position in the search results list.
Any terms that were matched in the selection process are listed in the PRIORITIZED TERMS section for each search results item.
Hovering over the term will reveal a tooltip that shows the specific fields that were matched and the relative contribution of each matched field to the terms overall score. If multiple occurrences of a term were matched in a single field the number of occurrences are shown in parentheses. The tooltip also provides two values, one showing the relative importance of that term to the document and the calculated relevance for the term. The calculated term relevance is based on its importance to the document and the term weight specified by the PRIORITIZED TERMS slider.
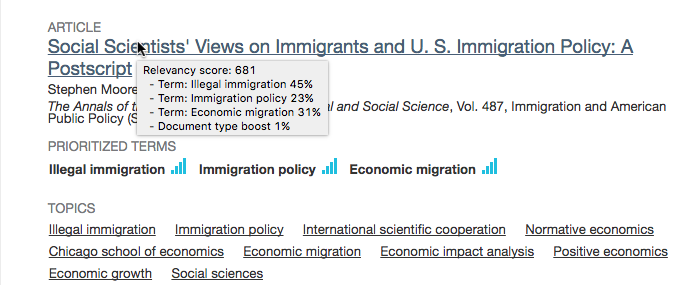
In the example below the term "Illegal immigration" was recognized as a topic in this document. One instance of the term was found in the abstract and four in the document body. The overall contribution of the term to the documents relevancy score was 307. This term also had document weight of 10 (on a scale of 1-10) indicating that it was extremely important to this document.

4. The factors contributing to the documents overall relevancy score (and thus its position in the results list) can be seen by hovering over the document title in the search results. This will show the overall score and the relative contribution of each matched term. If the I prefer recent content checkbox is selected a Publication date boost will also be used in the relevancy calculation and shown in the tooltip.
In the example below the document matched 3 terms, "Illegal immigration", "Immigration policy", and "Economic migration". Of these, "Illegal immigration" was the most significant, equal to 45% of the documents overall relevancy score. Changing the value of the slider associated with this term in the PRIORITIZED TERMS section would increase or decrease the calculated value for this term, possibly resulting in different ranking in the results list.
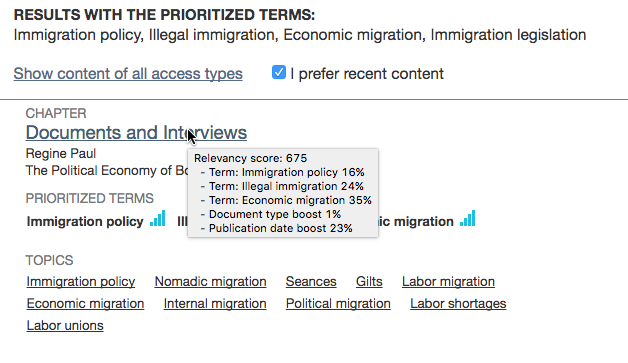
In this next example we see the affect of checking the I prefer recent content checkbox. A moderate boost is given to documents with more recent publication dates. In this instance, the document shown received a boost that represents 23% of the documents total relevancy score.
That does it for now. Watch this space for more information on the Text Analyzer. We're in the early stages of exploring how this tool might be used and will be continually improving it based on user feedback. We are also working on improvements to the analyses that are performed and will share more about that as things progress.